TREC 2026
Guidelines for Participants
Draft version, 2026-07-27
Track Overview
User simulation provides a scalable, cost-effective alternative to expensive human user studies when evaluating interactive search systems. However, the community currently lacks standardized methods for validating these simulators. The TREC User Simulation Track aims to establish a systematic framework for validating user simulators, determining the criteria for a reliable simulation, and creating best practices for simulation-based evaluation. For a comprehensive look at our long-term vision, please review the track’s Research Agenda.
The first edition of the track lays the groundwork for evaluating conversational simulators, with the specific goals of delivering (1) a robust standardized infrastructure for simulator-agent interactions, (2) a foundational dataset of both human and simulated conversational search logs, (3) initial evaluation baselines and behavioral metrics, and (4) a learned model capable of automatically predicting human-likeness scores.
Tasks
In this track, participants will develop a user simulator that mimics the behavior of a researcher using a conversational assistant to find datasets to help answer a specific research question.
Crucially, the conversational search assistant (the “agent”) will be provided by the track organizers. The sole focus for participating teams is to generate the user side of the dialogue, accurately simulating how a human researcher would query, clarify, and respond to the agent.
Participants can evaluate their simulators through two distinct tasks:
Task 1: Turn-level Next Utterance Prediction
This task focuses on a simulator’s ability to model the immediate, reactive behavior of a user at a single turn. It tests local conversational coherence and behavioral realism within an ongoing dialogue.
- Input: A scenario and a partial conversation history (a sequence of preceding user and system turns) and the simulated user’s underlying initial information need.
- Output: The single, predicted next user utterance. Participants may also include associated dialogue acts representing the semantic intent of the simulated utterance.
Task 2: Session-level End-to-End Conversation Generation
This task evaluates a simulator’s ability to strategically manage an entire conversation to achieve a predefined goal. It tests high-level planning, conversational persistence, and the simulator’s ability to recognize task success.
- Input: A scenario that specifies the simulated user’s persona and goals.
- Output: A complete, multi-turn conversation. The simulator must dynamically interact with the provided system, generating sequential turns until the simulator autonomously decides the goal is satisfied or that the search should be abandoned.
Scenarios
In traditional TREC tracks, systems are evaluated against a standardized set of “topics.” In the User Simulation Track, these are defined as scenarios. A scenario provides the foundational context that drives the simulated user’s behavior. Each scenario is constructed from three core components:
- Persona: The defining characteristics of the simulated user. This encompasses their background, communication style, and general technical proficiency.
- Goal: The specific information need. This details the exact type of dataset the user is attempting to find, as well as the broader research context or problem that is motivating their search.
- Persona-goal interaction: The intersection of the user’s background and their specific objective. This component defines the user’s domain expertise and familiarity with the subject matter.
Simulators must synthesize all three components of the scenario to maintain a consistent, realistic behavior throughout the conversation.
Training and Test Data
- Training data (participant-sourced): During the topic development phase, participating teams will be asked to interact directly with our development agents to accomplish a set of predefined training goals. For this collection, participants will act as themselves—reflecting their genuine characteristics, technical proficiency, and search habits rather than adopting a fictitious persona. The resulting interaction logs will be distributed to all teams to serve as the primary training and validation dataset.
- Test data (held-out evaluation): To establish a robust human baseline for the final evaluation, the organizers will collect a separate set of human conversations. This collection relies on a strictly distinct set of test goals and will be sourced independently (e.g., via organizers, students, and crowdsourced workers). The conversational logs from this test set will remain private during the submission phase and will be used to benchmark the submitted official runs.
In addition to the core datasets above, we release an external dataset focused on the exact same task (conversational dataset search). The dataset is a partial extension of an existing dataset (described in this paper). Crucially, this dataset includes think-aloud transcripts. While these logs were collected using different conversational agents than the ones provided in this track, the think-aloud data is specifically meant to provide deep insights into how real humans cognitively approach and strategize completing the dataset search task. This supplemental resource is intended to help teams bootstrap the early design of their simulators before the official training data becomes available.
Setup (API and Infrastructure)
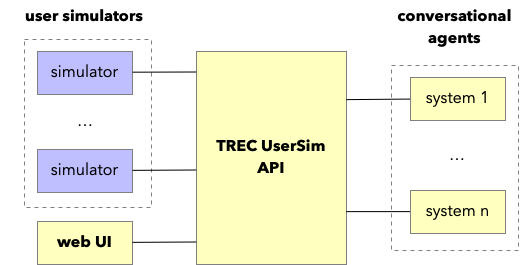
The evaluation environment relies on four components (illustrated in the figure above):
- Simulators: The user simulation models developed by participating teams.
- Conversational Agents: Systems designed for dataset search, provided by the track organizers, which the simulators will interact with.
- TREC UserSim API: The central broker that facilitates and standardizes all communication between users (simulated or human) and the conversational agents.
- Web Interface: A frontend exposing the conversational agents to human users, utilized by the organizers to collect baseline human interaction data.
Conversational Agents
The track provides two categories of conversational agents to assess how robustly a simulator adapts to different system behaviors and capabilities:
- Development Agents: Released during the initial phase to help participants design, tune, and test their simulators.
- Test Agents: Used exclusively during the data collection and official submission phases. These are the systems your simulators will interact with to generate the final submitted runs.
TREC UserSim API
The TREC UserSim API is the central gateway for all interactions in this track. It standardizes the communication between user simulators and the provided conversational agents, handling both the development phase and the orchestration of official run submissions. Its comprehensive documentation covers API endpoints, authentication, and expected request/response JSON formats.
The API is available at http://f03-iim-lin1.cit-f03.fh-koeln.de/api.
Submission Guidelines
Similar to TREC iKAT, the User Simulation Track relies on interactive submissions. Instead of submitting static document rankings, participants connect their user simulators to a live API endpoint (think of it as submitting user simulators instead of system rankings). Concretely, a run submission comprises the utterances of a single user simulator across multiple conversations, constructed from combinations of scenarios and conversational agents.
Participants may submit up to 4 official runs per task that are included in the evaluation. In addition, they are granted (n+1)×10 debug runs, where n is the number of training conversations contributed by the participating team, to support the development of their user simulators prior to official submission. Both official and debug runs use the same API, but with distinct endpoints. API access tokens will be distributed upon registration.
The user simulator completes a run submission, covering multiple scenario-agent combinations. The workflow for completing the run is a stream of client-side requests (from the user simulator) and responses from the infrastructure (based on the conversational agent). To help participants get started, the organizers provide a baseline simulator template that handles interaction with the infrastructure. It includes a detailed documentation for Task 1 and Task 2 workflows, including examples of requests and payloads.
Evaluation Measures
We will evaluate submissions using:
- Qualitative evaluation (human raters): A form of Turing Test, where trained annotators are presented with two dialogues and must attempt to guess which one is simulated.
- Behavioral metrics (quantitative log comparison): A comparison of simulated dialogues against real human usage logs, in terms of (the distributions of) key interaction behaviors (e.g., query length, turn count, clarification requests) and utilizing dialogue act annotations to model and compare semantic intent.
Timeline
- April: Draft guidelines released
- June: Training data collection begins (guidelines finalized)
- July: Training data collection complete
- July: System development begins (track API opens)
- September: Submissions due
- November: TREC Conference